Stop Polling: How to Build AI Agents That Actually React to the Real World
Let's be real. The typical chatbot is cool, but it's passive. It just sits there waiting for a prompt. We're now building AI agents that are supposed to be proactive—systems that can reason, plan, and do things on their own. But how do you get an AI to actually operate in the real world, a world that’s messy and always changing?
The answer isn't some new, complex AI model. It's a fundamental shift in architecture. We need to stop thinking in terms of request-response and start building systems that are event-driven. This is the story of how two old-school pieces of tech, Event-Driven Architecture (EDA) and the humble webhook, are making modern AI possible.
The Synchronous Trap We All Fall Into
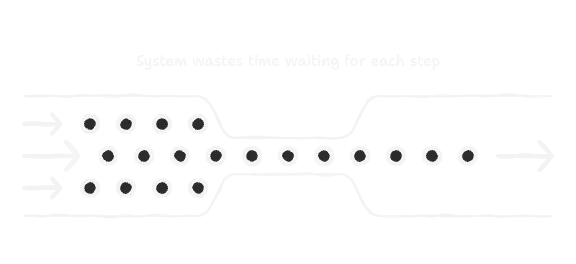
Most of us start out building AI tools that work synchronously. You send a request, the AI does its thing, you get a response. Simple. But it's a trap.
Imagine you've built an AI travel assistant. The user asks it to book a trip. Your code first calls a flight API, waits. Then it calls a hotel API, waits. Then it checks the weather, waits. The whole time, the user is just staring at a spinner. It feels clunky and slow because it *is* clunky and slow.
This one-track-mind approach causes a few big headaches:
- Bad UX: Nobody likes waiting. Forcing users or other systems to wait for a chain of tasks is a recipe for frustration.
- Wasted CPU Cycles: Your expensive server is literally sitting there doing nothing while it waits for a network call to return.
- No Real Multitasking: The agent can't juggle tasks. It's stuck on one thing at a time, which is useless for complex, real-world automation.
Flipping the Model: Event-Driven Architecture
The fix is to go asynchronous. Your AI agent should be able to fire off a request and immediately move on to something else. When the first task is done, it gets a notification—an event—and picks up the work.
This is the core idea behind Event-Driven Architecture (EDA). Instead of services calling each other directly, they communicate by firing off and listening for events. An "event" is just a message that says "hey, something happened," like `payment.succeeded` or `user.created`.
When you build your system this way, you get a ton of benefits. Your services are decoupled, which means:
- Scalability: If one service gets hammered with events, you can scale it up without touching anything else.
- Resilience: If your billing service goes down, it doesn't take the whole system with it. Events can be queued up and processed when it comes back online.
- Flexibility: Want to add a new feature? Just deploy a new service that listens for the same events. No need to rewrite existing code.
In this world, your AI agents become just another service, listening for events and firing off new ones. They become part of a reactive, living system.

Webhooks: The Glue for Your Event-Driven AI
So if EDA is the pattern, what’s the actual implementation? For most of us, it’s webhooks. A webhook is just an HTTP request that one system sends to another when an event happens.
People call them "reverse APIs" for a reason:
- The Old Way (Polling): Your app has to constantly ask an API, "Anything new? Anything new? Anything new?" It's annoying and inefficient.
- The Webhook Way (Push): The other system promises to call you the *instant* something happens. You just listen.
For an AI agent, webhooks are its eyes and ears. An incoming webhook tells it something happened in the world, and an outgoing webhook is how it tells the world what it did.
Examples of Webhooks Triggering AI Agents
This isn't theoretical. It's how modern automation actually works:
- Customer Support: A new ticket in Zendesk fires a webhook. Your agent wakes up, reads the ticket, checks internal docs, and drafts a reply.
- E-commerce: A `payment.succeeded` event from Stripe hits your webhook. An agent instantly updates the inventory database and calls a shipping API.
- DevOps: A `git push` to the main branch triggers a webhook. An AI agent reviews the code for common bugs and posts its findings to a Slack channel via another webhook.
The Hard Part: Moving from Prototype to Production
Okay, so you've got a cool demo working on your machine. But pushing a webhook-driven AI to production is where things get gnarly. You'll run into a bunch of problems that can, and will, break your system.
1. Security: Who's Calling You?
An open webhook endpoint is basically a backdoor into your system. You can't just trust any request that comes in. The standard way to lock this down is with HMAC signature verification. The sender signs the request with a secret key; you use the same key to verify it. If the signature doesn't match, you throw the request in the trash. No exceptions.
2. Reliability: What if You Miss a Call?
Networks are flaky. Your server will go down for deployment. What happens to webhooks that get sent during that time? If you don't have a plan, they're gone forever. A production-grade system needs:
- Retries: The sender (or a middleware) *must* retry failed requests, ideally with exponential backoff so you don't get DDoS'd by your own infrastructure.
- Dead-Letter Queues (DLQs): If a webhook keeps failing after a few retries, you don't just drop it. You move it to a "dead-letter queue" to be looked at by a human. Never lose an event.
- Idempotency: Because of retries, you *will* get the same event more than once. Your code needs to handle this gracefully. Processing the same `order.created` event twice shouldn't create two orders.
3. State Management: How Do You Remember Things?
HTTP is stateless, but AI agents need to remember the context of a conversation or a multi-step task. The only way to do this is to store the state somewhere else. A common pattern is to pass a `session_id` in the webhook. Your agent uses that ID to load the history from a database (like Redis), do its work, and save the new state before it finishes.
4. Observability: How Do You Debug a Ghost?
Debugging an autonomous, asynchronous system is a nightmare. The agent did something weird—why? Standard logs aren't enough. You need to be able to trace the agent's entire "chain of thought." This means logging the full payload of every webhook, every LLM prompt and response, and every API call it makes. Without that, you're flying blind.
The Smart Fix: Don't Build It Yourself, Use a Proxy
You could spend weeks building all that security, reliability, and logging infrastructure. Or you could just... not.
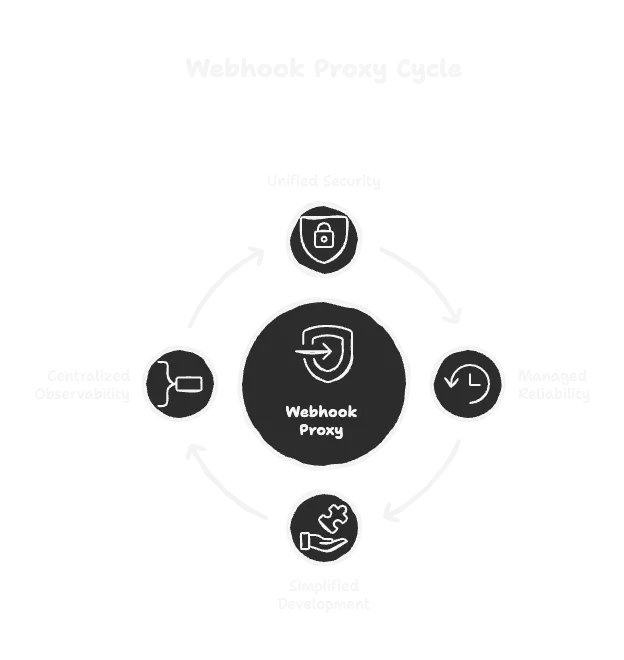
This is where a webhook proxy (or gateway) comes in. It's a dedicated service that sits in front of all your agents and handles the ugly parts of webhook management for you. Instead of every developer on your team reinventing the wheel, you solve these problems once at the infrastructure level.
A good webhook proxy gives you:
- Centralized Security: Handle signature validation in one place.
- Built-in Reliability: It manages ingestion, retries, and dead-letter queues automatically. Your developers can just focus on writing the agent's logic.
- Traffic Management: It can buffer traffic spikes and transform payloads, protecting your agents from being overwhelmed.
- Full Observability: You get a single, searchable audit trail of every single event that flows through your system. Debugging becomes possible again.
Build on a Solid Foundation
The future of AI is a bunch of specialized agents talking to each other and reacting to the world. That communication layer is built on events, and webhooks are the pipes that carry them.
But if those pipes are leaky, insecure, and you can't see what's flowing through them, your whole system is fragile. Getting your webhook infrastructure right isn't just an add-on; it's the foundation. By offloading the complexity of event management to a dedicated layer, you free up your developers to build AI that's not just smart, but also stable, secure, and actually works in the real world.